2 回答

一般这种就是非常典型的动态调控,常用的有下面几种做法:
1. 可以先把差异基因都找出来,然后做个heatmap
2. 把高变基因做个PCA看高权重基因;
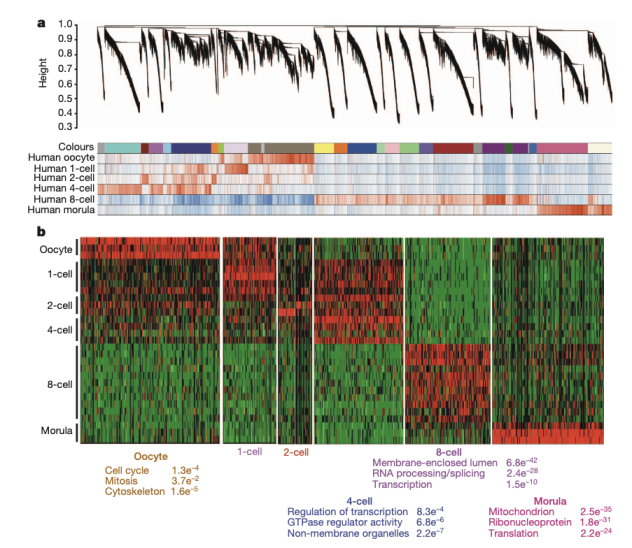
3. 尝试WGCNA,类似可参考这篇paper (https://www.nature.com/articles/nature12364)

其中就是利用WGCNA解决每个发育时期的响应基因的。