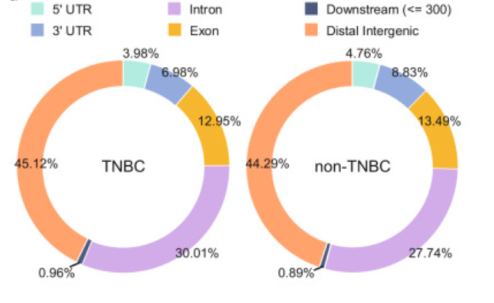
1 回答

要对peak进行基因组注释并得到其基因组分布,你可以使用工具annotatePeaks来完成。annotatePeaks是HOMER(Hypergeometric Optimization of Motif EnRichment)软件包中的一个功能,它可以将peak与基因组特征进行关联,提供详细的注释信息。
下面是如何使用annotatePeaks进行注释的步骤:
annotatePeaks.pl peakfile genome > outputfile运行命令后,annotatePeaks会将注释结果输出到指定的输出文件中,其中包含peak落在内含子、外显子、基因间区等各个区域的详细信息。
你可以使用文本编辑器或相关软件打开输出文件,查看注释结果。结果中的每一行代表一个peak,包含了peak的位置信息以及其在各个基因组区域的注释。
希望这个解答对你有所帮助!如果还有其他问题,请随时提问。