2 回答


#用blast的结果将qiime2分类器注释结果进行补全
temp1_taxonomy <- blast.tax[,1] %>% left_join(taxonomy, by = "OTU_ID")
#判断两个数据框每行的OTU是否对应,才能开始下一步
blast.tax$OTU_ID == temp1_taxonomy$OTU_ID
#改为数据框格式
blast.tax <- blast.tax %>% as.data.frame()
temp1_taxonomy <- temp1_taxonomy %>% as.data.frame()
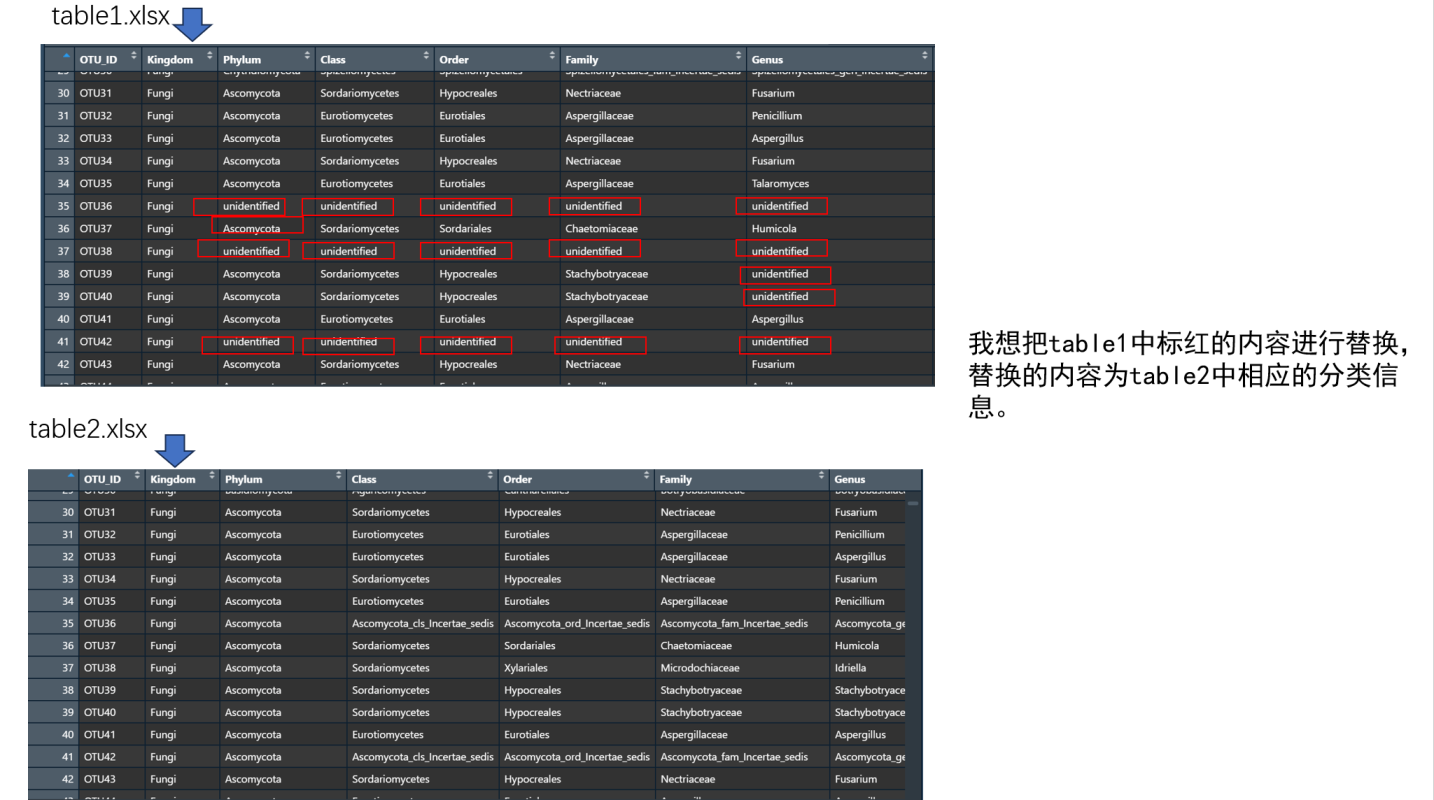
# 获取第一个表格【temp1_taxonomy】中 "unidentified" 值的位置信息
coordinate_information <- which(temp1_taxonomy == "unidentified", arr.ind = TRUE)
# 使用位置信息从第二个表格【blast.tax】中提取对应位置的值
replacement_values <- blast.tax[coordinate_information]
# 将第一个表格中的 "unidentified" 值替换为第二个表格中对应位置的值
temp1_taxonomy[temp1_taxonomy == "unidentified"] <- replacement_values